
In recent years, different groups at CERN started looking at using containers for different purposes, covering infrastructure services but also end user applications. These efforts have been mostly done independently, resulting in a lot of repeated work especially for the parts which are CERN specific: integration with the identity service, networking and storage systems. In many cases, the projects could not complete before reaching a usable state, as some of these tasks require significant expertise and time to be done right. Alternatively, they found different solutions to the same problem which led to further complexity for the supporting infrastructure services. However, the use cases were real, and a lot of knowledge had been built on the available tools and their capabilities.
Based on this, we started a project with the following goals:
Looking for other possibilities, OpenStack Magnum seemed to be offering a lot of what we needed, and we decided to try it out. At around the same time we were also heading to the OpenStack Tokyo summit, which was a great opportunity to follow the Magnum sessions and learn more of what it provides.
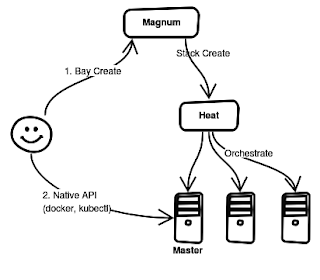 Magnum relies heavily on Heat for the orchestration part of the container clusters - called bays. Bays are instantiated based on pre-defined bay models, which set how the master and the other nodes should look like (flavor, image, etc) and which container orchestration engine (COE) should be used - among other possible configuration options. Current choices include Docker Swarm, Kubernetes and Mesos. The Magnum homepage gives a lot more details.
Magnum relies heavily on Heat for the orchestration part of the container clusters - called bays. Bays are instantiated based on pre-defined bay models, which set how the master and the other nodes should look like (flavor, image, etc) and which container orchestration engine (COE) should be used - among other possible configuration options. Current choices include Docker Swarm, Kubernetes and Mesos. The Magnum homepage gives a lot more details.
At the beginning of November 2015, we started investigating the Magnum project in depth. At that time the project was functional but some of its requirements posed problems in our deployment:
Based on this, we started a project with the following goals:
- integrate containers into the CERN OpenStack cloud, building on top of already available tools such as resource lifecycle, quotas, identity and authorization
- stay container orchestration agnostic, allowing users to select any of the most common solutions (Docker Swarm, Kubernetes, Mesos)
- allow fast cluster deployment and rebuild
Looking for other possibilities, OpenStack Magnum seemed to be offering a lot of what we needed, and we decided to try it out. At around the same time we were also heading to the OpenStack Tokyo summit, which was a great opportunity to follow the Magnum sessions and learn more of what it provides.
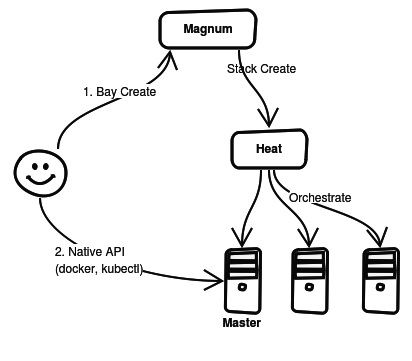
At the beginning of November 2015, we started investigating the Magnum project in depth. At that time the project was functional but some of its requirements posed problems in our deployment:
- Dependency on OpenStack Neutron, something we had not yet deployed (we have nova-network since we started the cloud in 2012). Luckily we were working on it in parallel, and we got a functional control plane just in time. And as we use Nova Cells, we could enable Neutron in a dedicated cell where we would also enable Magnum, reusing the rest of the production infrastructure
- Requirement on Neutron LBaaS, which we don't have. This is something we plan to try, but it is not obvious how to implement this currently due to the way the CERN network is structured. We made some changes to the Heat templates to remove this requirement
The other pre-requisite projects, such as Keystone, Glance and Heat were already in production in the CERN cloud.
But no real show stoppers and very quickly we got a prototype deployment. For a more detailed evaluation we initially chose 3 internal projects that cover the most common use cases:
For our users and resource managers, there are significant advantages of the Magnum approach:
- GitLab CI, a continuous integration service we use internally - it has integration with Docker, making it a perfect example of how to use a Docker Swarm cluster as a drop in replacement for a local Docker daemon
- Infrastructure services, namely one of the critical services for the data movement between the multiple sites of the LHC Computing Grid (WLCG) - for a nice example of scaling a service by scaling its individual components
- Jupyter Notebooks - a growing trend for end user analysis in different scientific communities, providing a browser based interactive session running in a remote container
In addition, we are also working with the European Union Horizon 2020 project Indigo Datacloud which is developing an open source data and computing platform targeted at scientific communities, deployable on multiple hardware and provisioned over hybrid, private or public, e-infrastructures. Using Magnum, we can provide the test resources for this project to the partners.
For our users and resource managers, there are significant advantages of the Magnum approach:
- Native tools - anything that works with Docker will work talking to a Docker Swarm COE or kubectl with a Kubernetes cluster. This allows smaller physics sites to provide native Docker or Kubernetes while the larger sites provide Containers-as-a-Service on-demand. User applications written to work with Docker or Kubernetes can be used without modification against the provisioned resources.
- Container engine agnostic - with our user community, there is a strong need for flexibility to allow different avenues to be explored. Magnum allows the IT department to offer Kubernetes, Docker Swarm and Mesos at a low cost within the same service at an affordable load for the support team. The users can then prototype different application approaches and select the best combination for them. Enforcing a central IT service decision on the end user community is never easy, especially where there are diverse user requirements being covered within a central cloud.
- Accounting, quota and permissions remains within the existing framework. Thus, whether resources are used for containers or VMs is a choice for the project user. Capacity planning can be done by cores/RAM rather than segmentation of resources for container or VM resources. Access controls follow the existing admin/member structures for projects.
- Elasticity - within the quota limits, containers can scale, with new bays as needed within the quota. This allows the resources to be allocated where there is a user need (and as importantly, shrunk when things are quiet)
- Repairs - failures in the infrastructure (software or hardware) are looked after by the cloud support team. For the user, the workloads can be scheduled elsewhere. For the hardware repair teams, the operations can be performed in a consistent fashion in bulk rather than on a one-by-one basis. Infrastructure monitoring procedures are the same for VMs and containers.
- The operating system support teams can provide reference images and follow up issues with the upstream providers. They can be confident that the image is based on supported configurations rather than ad-hoc builds. Rebuilding base images with the appropriate security patches can sometimes be delayed, raising the risk of incidents.
By the end of March, we had the use cases covered, and the few hick-ups covered in blueprints or patches upstream, and had contributed for the missing bits in puppet and documentation. And with a service running on our production resources and thanks to keystone endpoint filtering, we could increase service usage by enabling it for individual projects. Today we have around 15 different projects using Magnum as a pilot service and the number keeps growing.
In just a few months, we got Magnum up and running and it has proved to be a significant addition to the OpenStack cloud. Which makes us excited about what is coming next, including:
In just a few months, we got Magnum up and running and it has proved to be a significant addition to the OpenStack cloud. Which makes us excited about what is coming next, including:
- Integration with Cinder - ready upstream, and we'll be trying it very soon
- Magnum benchmarks in Rally - we rely on Rally to make sure our cloud is performing as expected
- Further integration with our local storage systems such as CVMFS and EOS - relying on the ability to add site specific configurations to the bay templates
- Integration with Barbican - the recommended way to handle the required TLS certificates to talk to the native APIs of the orchestration engines, and the only option today to get Magnum in HA (though that's about to change)
- Integration with Horizon - this will help as we expand the service into production to communities who are used to using the web interfaces
If you're interested in more details on the available container orchestration technologies or our usage of OpenStack Magnum, or simply want to see some fancy demos, check our recent presentation at a CERN Technical Forum.
Acknowledgments
- Mathieu Velten for his work on testing and adapting Magnum at CERN and contributions to Indigo DataCloud
- Bertrand Noel for all his time spent researching existing container technologies
- Spyros Trigazis, a fellow in the CERN OpenLab collaboration with Rackspace, for all his work upstream both for features and documentation improvements
- Jarek Polok for the CERN docker repository
- The OpenStack Magnum team for their support and collaboration
- All CERN users that helped us debug and set the service requirements
References
- Presentation on containers at the CERN Technical Forum - https://cds.cern.ch/record/2144886
- End user documentation at http://clouddocs.web.cern.ch/clouddocs/containers/index.html
- OpenStack superuser article at http://superuser.openstack.org/articles/openstack-magnum-on-the-cern-production-cloud
Really you have done a great job, There are may person searching about that topic. now they will easily find your post
ReplyDeleteDocker Training in Hyderabad
Kubernetes Training in Hyderabad
Docker and Kubernetes Training
Docker and Kubernetes Online Training
Hi,
ReplyDeleteCertified data center professional
A certified data center expert must understand the design life cycle of the data center and the various stages included. It is your responsibility to follow the levels of redundancy for the design and configuration of the data center.
For More: Certified data center professional
I work as a marketing specialist and staff author at Externetworks which is a pioneer in Managed Technology Services with over 17+ years of experience in providing end-to-end solutions featuring design, deployment and 24*7 support to top IT companies. We offer world-class managed services for businesses to stay agile & profitable. Our services include 24/7 Network Monitoring, Uptime maintenance, NOC Support, IT Helpdesk services.
ReplyDeleteRead more at: Career of a NOC Technician
Thank you sharing this Information
ReplyDeleteI also found Various useful links related to Devops, Docker & Kubernetes
Kubernetes Kubectl Commands CheatSheet
Introduction to Kubernetes Networking
Basic Concept of Kubernetes
Kubernetes Interview Question and Answers
Kubernetes Sheetsheat
Docker Basic Tutorial
Linux Sar Command Tutorial
Linux Interview Questions and Answers
Docker Interview Question and Answers
OpenStack Interview Questions and Answers
Nice post, very useful blogs with very useful information, thank you for sharing this post noc monitoring services
ReplyDeleteOur experience with students enables us to determine the fastest and most effective teaching methods that, Allah willing, make them achieve the best results in memorization of the Holy Quran within the shortest possible period of time misinterpretation of the quran
ReplyDeleteThis article is deserving of acknowledgment and remark. I discovered this material eye catching and charming. This is very much scripted and profoundly useful. These perspectives offer to me. This is the way genuine composing is finished. Much thanks to you.
ReplyDeleteSEO services in kolkata
Best SEO services in kolkata
SEO company in kolkata
Best SEO company in kolkata
Top SEO company in kolkata
Top SEO services in kolkata
SEO services in India
SEO copmany in India
This article contains some of the most informative content I've read in quite some time. The points of this content are clear-cut and engaging. I think much like this writer.
ReplyDeleteDenial management software
Denials management software
Hospital denial management software
Self Pay Medicaid Insurance Discovery
Uninsured Medicaid Insurance Discovery
Medical billing Denial Management Software
Self Pay to Medicaid
Charity Care Software
Patient Payment Estimator
Underpayment Analyzer
Claim Status
To be honest I found very helpful information your blog thanks for providing us such blog IPL Betting
ReplyDeleteTo be honest I found very helpful information your blog thanks for providing us such blog Dream11 IPL 2020: DC vs RCB Preview
ReplyDeleteThis is really best article for new internet users , You are a very skilled blogger and content writing. I’ve joined your feed and look forward to seeking more of your excellent and so helpful post. Also, I’ve shared your website in my Facebook! Thank you. assignments help australia -
ReplyDeletenursing assignment help -
university assignment help australia
My friend suggested I might like this article website. He was saying right that you blog very informative and match our study. I agree with her. Your content is very helpful for me; I am also writing on educational topics, I really like thanks so much.
ReplyDeleteI have voiced some of the articles info on your website now and, I really like your blogging style and many ideas. I added it to my list of favorite blogging website and will be back soon. Thank you my dear friend for sharing many useful thoughts.
ReplyDeletemyob assignment help -
assignment writers -
buy assignment online
Is it accurate to say that you are feeling stuck under a monster heap of your confounded and extensive programming assignments, which appear hard to wrap up? Indeed, fret no more. At ABC, we can help you with probably the most capable programming assignment specialists who can help you with your assignments at the most moderate and pocket-accommodating rates. programming assignment help , matlab assignment help
ReplyDeleteAssignment help from GoAssignmentHelp is surely a thing you don't want to miss out on. AssignmentHelp offers you the law assignment help in Australia. GoAssignmentHelp has a team of highly experienced writers programming assignment help they have already set a benchmark with their work all around the world. Our team consists of many Ph.D. assignment experts who will help you with expert java assignment help assistance in every way possible.
ReplyDeleteHello to all, it’s genuinely a pleasant for me to pay a quick visit this website, it includes valuable Information. 야설
ReplyDeleteI finally found great post here. 카지노사이트 Thanks for the information. Please keep sharing more articles.
ReplyDeleteThank you for sharing this information. I read your blog and I can't stop my self to read your full blog. 토토사이트 Again Thanks and Best of luck to your next Blog in future.
ReplyDeleteThanks for writing this informative content, keep sharing.
ReplyDeleteThe right sales tracker software will help you identify the root cause behind restricted sales. The right steps will allow sales staff to easily analyze customers' actions. This means that sales success is largely dependent on the sales process.
I like what you guys are up also. Such clever work and reporting! Carry on the excellent works guys I?|ve incorporated you guys to my blogroll. I think it will improve the value of my website. 바카라사이트
ReplyDeleteIt’s always a pleasure to read your magnificent articles on this site. You are among the top writers of this generation, and there’s nothing you can do that will change my opinion on that. My friends will soon realize how good you are. 토토사이트
ReplyDeleteAssignment writing is a significant difficult undertaking for generally every one of the students. What makes it significantly more upsetting is the impact it has on the grades and the moving toward cutoff times. In case you are ending up under these burdening conditions and are wildly looking for some assignment help to back out the entire cycle for you, then, at that point ABC assignment help is your all inclusive resource. matlab assignment help
ReplyDeleteWow! Such an amazing article I really really loving your each blogs which your sharing on this website. It's so good and so awesome, Trust me guys, you archive so big goals after shar like this post on internet. I hope that you continue to do your work like this in the future also. Thank you and Wish you very good luck for your many new postings. Australia Assignment Help - best assignment help in brisbane - best assignment help in perth - Online Assignment Help
ReplyDeleteThe information shared is really helpful and so useful to get to know about various suggestions and the information shared is rich in content. Please keep us up to date like this work in future also. Thanks for sharing your knowledge and, I'm glad I came into this article because it provides a lot of important information. Keep it guys. You doing so well, I know that :) nursing assignment help - english assignment help - case study help
ReplyDeleteHow to get a cash app refund if a transaction is sent to the wrong person?
ReplyDeleteHow to get a Cash App Refund if a transaction is sent to the wrong person? Like many other cash app users if you also want the answer of this question then you have knocked on the right door. You will know here how to get a refund on the cash app if the money is sent to the wrong person, you just have to click on this link and after that, it’s just a matter of seconds.
Supply chain management assignment:: This subject spotlights on dealing with the progression of labor and products from natural substances into end results. Assuming you think that it is precarious to deal with the subjects of this subject, then, at that point, take inventory network the executives assignment composing administrations in Australia and free yourself from composing stresses. my assignment help
ReplyDeleteExcellent work Online Assignment help
ReplyDeleteI was very impressed by the information you have provided. In fact, being aware of what is going on in the rest of the world is extremely beneficial. I feel more confident in my ability to think after reading this post sequence. I'd like to connect with you via the ISO Certification and Training service for better feedback. Keep up the excellent work. Read this blog : ISO 45001 Certification in Singapore
ReplyDeleteVery Simple 메이저토토사이트추천 Win Strategy (Symmetry Strategy)
ReplyDeleteI blog often and I seriously appreciate your information. Your article has really peaked my interest. I will bookmark your blog and keep checking for new information about once per week. Thank you so much for sharing. Also visit coeeki departmental cut off mark
ReplyDeleteHey friend, it is very well written article, thank you for the valuable and useful information you provide in this post. Keep up the good work! 룰렛
ReplyDeleteThis sort of clever work and exposure! Keep up the awesome work. I appreciate you for sharing this great impressive piece. Its educative! Thank you for sharing. Also visit free gre past questions
ReplyDeleteThis comment has been removed by the author.
ReplyDelete