
As part of the recent OpenStack summit in Austin, the Scientific Working group was established looking into how scientific organisations can best make use of OpenStack clouds.
During our discussions with more than 70 people (etherpad), we concluded on 4 top areas to look at and started to analyse the approaches and common needs. The areas were
- Parallel file system support in Manila. There are a number of file systems supported by Manila but many High Performance Computing sites (HPC) use Lustre which is focussed on the needs of the HPC user community.
- Bare metal management looking at how to deploy bare metal for the maximum performance within the OpenStack frameworks for identity, quota and networking. This team will work on understanding additional needs with the OpenStack Ironic project.
- Accounting covering the wide range of needs to track usage of resources and showback/chargeback to the appropriate user communities.
- Stories is addressing how we collect requirements from the scientific use cases and work with the OpenStack community teams, such as the Product working group, to include these into the development roadmaps along with defining reference architectures on how to cover common use cases such as high performance or high throughput computing clouds in the scientific domain.
Given limited time available, it was not possible for each of the interested members of the accounting team to explain their environment. This blog is intended to provide the details of the CERN cloud usage, the approach to resource management and some areas where OpenStack could provide additional function to improve the way we manage the accounting process. Within the Scientific Working group, these stories will be refined and reviewed to produce specifications and identify the potential communities who could start on the development.
CERN Pledges
The CERN cloud provides computing resources for the Large Hadron Collider and other experiments. The cloud is currently around 160,000 cores in total spread across two data centres in Geneva and Budapest. Resources are managed world wide with the World Wide Computing LHC Grid which executes over 2 million jobs per day. Compute resources in the WLCG are allocated via a pledge model. Rather than direct funding from the experiments or WLCG, the sites, supported by their government agencies, commit to provide compute capacity and storage for a period of time as a pledge and these are recorded in the REBUS system. These are then made available using a variety of middleware technologies.Given the allocation of resources across 100s of sites, the experiments then select the appropriate models to place their workloads at each site according to compute/storage/networking capabilities. Some sites will be suitable for simulation of collisions (high CPU, low storage and network). Others would provide archival storage and significant storage IOPS for more data intensive applications. For storage, the pledges are made in capacity on disk and tape. The compute resource capacity is pledges in Kilo-HepSpec06 units, abbreviated to kHS06 (based on a subset of the Spec 2006 benchmark) that allows faster processors to be given a higher weight in the pledge compared to slower ones (as High Energy Physics computing is an embarrassingly parallel high throughput computing problem).
The pledges are reviewed on a regular basis to check the requests are consistent with the experiments’ computing models, the allocated resources are being used efficiently and the pledges are compatible with the requests.
Within the WLCG, CERN provides the Tier-0 resources for the safe keeping of the raw data and performs the first pass at reconstructing the raw data into meaningful information. The Tier-0 distributes the raw data and the reconstructed output to Tier 1s, and reprocesses data when the LHC is not running.
Procurement Process
The purchases for the Tier-0 pledge for compute is translated into a formal procurement process. Given the annual orders exceed 750 KCHF, the process requires a formal procedure:
- A market survey to determine which companies in the CERN member states could reply to requests in general areas such as compute servers or disk storage. Typical criteria would be the size of the company, the level of certification with component vendors and offering products in the relevant area (such as industry standard servers)
- A tender which specifies the technical specifications and quantity for which an offer is required. These are adjudicated on the lowest cost compliant with specifications criteria. Cost in this case is defined as the cost of the material over 3 years including warranty, power, rack and network infrastructure needed. The quantity is specified in terms of kHS06 with 2GB/core and 20GB storage/core which means that the suppliers are free to try different combinations of top bin processors which may be a little more expensive or lower performing ones which would then require more total memory and storage. Equally, the choice of motherboard components has significant flexibility within the required features such as 19” rack compatible and enterprise quality drives. The typical winning configurations recently have been white box manufacturers.
- Following testing of the proposed systems to ensure compliance, an order is placed with several suppliers, the machines manufactured, delivered, racked-up and burnt it using a set of high load stress tests to identify issues such as cooling or firmware problems.
Typical volumes are around 2,000 servers a year in one or two rounds of procurement. The process from start to delivered capacity takes around 280 days so bulk purchases are needed followed by allocation to users rather than ordering on request. If there are issues found, this process can take significantly longer.
Given the time the process takes, there are only one to two procurement processes run per year. This means that a continuous delivery model cannot be used and therefore there is a need for capacity planning on an annual basis and to find approaches to use the resources before they are allocated out to their final purpose.
Physical Infrastructure
Step
|
Time (Days)
|
Elapsed (Days)
|
User expresses requirement
|
0
|
|
Market Survey prepared
|
15
|
15
|
Market Survey for possible vendors
|
30
|
45
|
Specifications prepared
|
15
|
60
|
Vendor responses
|
30
|
90
|
Test systems evaluated
|
30
|
120
|
Offers adjudicated
|
10
|
130
|
Finance committee
|
30
|
160
|
Hardware delivered
|
90
|
250
|
Burn in and acceptance
|
30 days typical with 380 worst
case
|
280
|
Total
|
280+ Days
|
Given the time the process takes, there are only one to two procurement processes run per year. This means that a continuous delivery model cannot be used and therefore there is a need for capacity planning on an annual basis and to find approaches to use the resources before they are allocated out to their final purpose.
Physical Infrastructure
CERN manages two data centres in Meyrin, Geneva and Wigner, Budapest. The full data is available at the CERN data centre overview page. When hardware is procured, the final destination is defined as part of the order according to rack space, cooling and electrical availability.
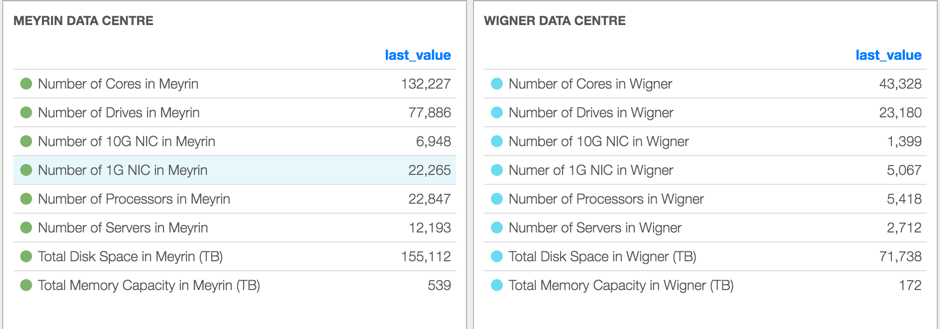
While the installations in Budapest are new installations, some of the Geneva installations involve replacing old hardware. We typically retire hardware between 4 and 5 years old when the CPU power/watt is significantly better with new purchases and the hardware repair costs for new equipment are more predictable and sustainable.
Within the Geneva centre, there are two significant areas, physics and redundant power. Physics power has a single power source which is expected to fail in the event of an electricity cut lasting beyond the few minutes supported by the battery units. The redundant power area is backed by diesels. The Wigner centre is entirely redundant.
Lifecycle
With an annual procurement cycle with 2-3 vendors per cycle, each one with their own optimisations to arrive at the lowest cost for the specifications, the hardware is highly heterogeneous. This has a significant benefit when there are issues, such as disk firmware or BMC controllers, that lead to delays in one of the deliveries being accepted, so the remaining hardware can be made available to experiments.
However, we run the machines for the 3 year warranty and then some additional years on minimal repairs (i.e. simple parts are replaced with components from servers of the same series), we have around 15-20 different hardware configurations for compute servers active in the centre at any time. There are variations in the specifications (as technologies such as SSDs and 10Gb Ethernet became commodity, the new tenders needed these) and those between vendor responses for the same specifications (e.g. slower memory or different processor models).
These combinations do mean that offering standard flavors for each hardware complication would be very confusing for the users, given that there is no easy way for a user to know if resources are available in a particular flavor except to try to create a VM with that flavor.
Given new hardware deliveries and limited space, there are equivalent retirement campaigns. The aim is to replace the older hardware by more efficient newer boxes that can deliver more HS06 within the same power/cooling envelope. The process to empty machines depends on the workloads running on the servers. Batch workloads generally finish within a couple of weeks so setting the servers to no longer accept new work just before the retirements is sufficient. For servers and personal build/test machines, we aim to migrate the workloads to capacity on new servers. This operation is increasingly being performed using live migration and MPLS to extend the broadcast domains for networks to the new capacity.
Projects and Quota
All new users are allocated a project, “Personal XXXX” where XXXX is their CERN account when they subscribe to the CERN cloud service through the CERN resource portal. The CERN resource portal is the entry point to subscribe to the many services available from the central IT department and for users to list their currently active subscriptions and allocations. The personal projects have a minimal quota for a few cores and GBs of block storage so that users can easily follow the tutorial steps on using the cloud and create simple VMs for their own needs. The default image set is available on personal projects along with the standard ‘m’ flavors which are similar to the ones on AWS.
Shared projects can also be requested for activities which are related to an experiment or department. For these resources, a list of people can be defined as administrators (through CERN’s group management system e-groups) and a quota for cores, memory and disk space requested. Additional flavors can also be asked for according to particular needs such as the CERNVM flavors with a small system disk and a large ephemeral one.
The project requests go through a manual approval process, being reviewed by the IT resource management to check the request against the pledge and the available resources. An adjustment of the share of the central batch farm is also made so that the sum of resources for an experiment continues to be within the pledge.
Once the resource request has been manually approved, the ticket is then passed to the cloud team for execution. Rundeck provides us with a simple tool for performing high privilege operations with good logging and recovery. This is used in many of our workflows such as hardware repair. The Rundeck procedure reads the quota settings from the ticket and executes the appropriate project creation and role allocation requests to Keystone, Nova and Cinder.
All new users are allocated a project, “Personal XXXX” where XXXX is their CERN account when they subscribe to the CERN cloud service through the CERN resource portal. The CERN resource portal is the entry point to subscribe to the many services available from the central IT department and for users to list their currently active subscriptions and allocations. The personal projects have a minimal quota for a few cores and GBs of block storage so that users can easily follow the tutorial steps on using the cloud and create simple VMs for their own needs. The default image set is available on personal projects along with the standard ‘m’ flavors which are similar to the ones on AWS.
Shared projects can also be requested for activities which are related to an experiment or department. For these resources, a list of people can be defined as administrators (through CERN’s group management system e-groups) and a quota for cores, memory and disk space requested. Additional flavors can also be asked for according to particular needs such as the CERNVM flavors with a small system disk and a large ephemeral one.
The project requests go through a manual approval process, being reviewed by the IT resource management to check the request against the pledge and the available resources. An adjustment of the share of the central batch farm is also made so that the sum of resources for an experiment continues to be within the pledge.
Once the resource request has been manually approved, the ticket is then passed to the cloud team for execution. Rundeck provides us with a simple tool for performing high privilege operations with good logging and recovery. This is used in many of our workflows such as hardware repair. The Rundeck procedure reads the quota settings from the ticket and executes the appropriate project creation and role allocation requests to Keystone, Nova and Cinder.
Need #1 : CPU performance based allocation and scheduling
As with all requests, there is a mixture of requirements and implementation. The needs are stated according to our current understanding. There may be alternative approaches or compromises which would address these needs in common with other user requirements. One of the aims of the Scientific Working group is to expose these ideas to other similar users, adapt them to meet the general community and work with the product working group, user committee and developers on an approach. Thus, the subsequent areas where CERN would be interested in improvements in the underlying software techologies.
The resource manager for the cloud in a high throughput/performance computing environment allocates resources based on performance rather than pure core count.
A user wants to request a processor of a particular minimum performance and is willing to have a larger reduction in his remaining quota.
A user wants to make a request for resources and then iterate according to how much performance related quota they have left to fill the available quota, e.g. give me a VM with less than a certain performance rating.
A resource manager would like to encourage the use of older resources which are often idle.
A quotas for slower and faster cores is currently the same (thus users create a VM, delete it if it is one of the slower type) so there is no incentive to use the slower cores.
As a resource manager preparing an accounting report, the faster cores should have a higher weight against the pledge to ensure continued treatment of slower cores.
The proposal is therefore to have an additional, optional quota on CPU units so that resource managers can allocate out total throughput rather than per core capacities.
The alternative approach of defining a number of flavors for each of the hardware types and quota. However, there are a number of drawbacks with this approach:
As with all requests, there is a mixture of requirements and implementation. The needs are stated according to our current understanding. There may be alternative approaches or compromises which would address these needs in common with other user requirements. One of the aims of the Scientific Working group is to expose these ideas to other similar users, adapt them to meet the general community and work with the product working group, user committee and developers on an approach. Thus, the subsequent areas where CERN would be interested in improvements in the underlying software techologies.
The resource manager for the cloud in a high throughput/performance computing environment allocates resources based on performance rather than pure core count.
A user wants to request a processor of a particular minimum performance and is willing to have a larger reduction in his remaining quota.
A user wants to make a request for resources and then iterate according to how much performance related quota they have left to fill the available quota, e.g. give me a VM with less than a certain performance rating.
A resource manager would like to encourage the use of older resources which are often idle.
A quotas for slower and faster cores is currently the same (thus users create a VM, delete it if it is one of the slower type) so there is no incentive to use the slower cores.
As a resource manager preparing an accounting report, the faster cores should have a higher weight against the pledge to ensure continued treatment of slower cores.
The proposal is therefore to have an additional, optional quota on CPU units so that resource managers can allocate out total throughput rather than per core capacities.
The alternative approach of defining a number of flavors for each of the hardware types and quota. However, there are a number of drawbacks with this approach:
- The number of flavors to define would be significant (in CERN’s case, around 15-20 different hardware configurations multiplied by 4-5 sizes for small, medium, large, xlarge, ...)
- The user experience impact would be significant as the user would have to iterate over the available flavors to find free capacity. For example, trying out m4.large first and finding the capacity was all used, then trying m3.large etc.
Extendible resource tracking seems to be approaching the direction with ‘compute units’ (such as here) as defined in the specification. Many parts of this are not yet implemented so it is not easy to see if it addresses the requirements.
Need #2 : Nested Quotas
As an experiment resource co-ordinator, it should be possible to re-allocate resources according to the priorities of the experiment without needing action by the administrators. Thus, moving quotas between projects which are managed by the experiment resource co-ordinators within the pledge allocated by the WLCG.
Nested keystone projects have been in the production release since Kilo. This gives the possibility for role definitions within the nested project structure.
The implementation of the nested quota function has been discussed within various summits for the past 3 years. The first implementation proposal, Boson, was for a dedicated service for quota management. However, there were concerns raised by the PTLs on the impacts for performance and maintainability of this approach. The alternative of enhancing the quotas in each of the projects has been followed (such as Nova). These implementations though have not advanced due to other concerns with quota management which are leading towards a common library, delimiter, which is being discussed for Newton.
Need #3 : Spot Market
As a cloud provider, uncommitted resources should be made available at a lower cost but at a lower service level, such as pre-emption and termination at short notice. This mirrors the AWS spot market or the Google Pre-emptible instances. The benefits would be higher utilization of the resources and ability to provide elastic capacity for reserved instances by reducing the spot resources.
A draft specification for this functionality has been submitted along with the proposal which is currently being reviewed. An initial implementation of this functionality (called OpenStack Preemptible Instances Extension, or opie) will be made available soon on github following the work on Indigo Datacloud by IFCA. A demo video is available on YouTube.
Need #4 : Reducing quota below
utilization
As an experiment resource co-ordinator, quotas are under regular adjustment to meet the chosen priorities. Where a project has a lower priority but high current utilization, further resource usage should be blocked but existing resources not deleted since the user may still need to complete the processing on those VMs. The resource co-ordinator can then contact the user to encourage the appropriate resources to be deleted.
To achieve this function, one approach would be to allow the quota to be set below the current utilization in order to give the project administrator the time to identify the resources which would be best to be deleted in view of the reduced capacity.
Need #5 : Components without quota
As a cloud provider, some inventive users are storing significant quantities of data in the Glance image service. There is only a maximum size limit with no accumulated capacity leaves this service open to non-planned storage.
It is proposed to add quota functionality inside Glance for
- The total capacity of images stored in Glance
- The total capacity of snapshots stored in Glance
Given that this is new functionality, it could also be a candidate for the first usage of the new delimiter library.
Need #6 : VM Expiration
As a private cloud provider, some VMs should be time limited to ensure that they are still required by their end users and automatically expire if there is no confirmation. Personal projects are often in this category as users will launch test instances but fail to delete them on completion of the test. These cases the users should be required to confirm that they will need the resources and that these are within their current allocated quota (Need #4).
Acknowledgements
There are too many people who have been involved in the resource management activities to list here. The teams contributing to the description above are:- CERN IT teams supporting cloud, batch, accounting and quota
- BARC, Mumbai for collaborating around the implementation of nested quota
- Indigo Datacloud team for work on the spot market in OpenStack
- Other labs in the WLCG and the Scientific Working Group
Very nice blog, Thanks for sharing grate article.
ReplyDeleteYou are providing wonderful information, it is very useful to us.
Keep posting like this informative articles.
Thank you.
From: Field Engineer
Network Field Technician Jobs
Technology Write For Us (Guest Posts) – Here in WebUpdatesDaily we are providing the opportunity to post your Technology, Business and many more other category blogs.
ReplyDeletegadgets write for us
Thank you sharing this Information
ReplyDeleteI also found Various useful links related to Devops, Docker & Kubernetes
Kubernetes Kubectl Commands CheatSheet
Introduction to Kubernetes Networking
Basic Concept of Kubernetes
Kubernetes Interview Question and Answers
Kubernetes Sheetsheat
Docker Basic Tutorial
Linux Sar Command Tutorial
Linux Interview Questions and Answers
Docker Interview Question and Answers
OpenStack Interview Questions and Answers
So far, I agree with you on much of the info you have written here. I will have to think some on it, but overall this is a wonderful article.
ReplyDeleteDenial management software
Denials management software
Hospital denial management software
Self Pay Medicaid Insurance Discovery
Uninsured Medicaid Insurance Discovery
Medical billing Denial Management Software
Self Pay to Medicaid
Charity Care Software
Patient Payment Estimator
Underpayment Analyzer
Claim Status
Tech Today Info has been sharing the best research information available in the area
ReplyDeleteof technology. We feature Tech Trends, Tips of Technology, and explore to tech
innovative products. Keep up to date on the latest developments in the tech
industry.
Write For Us Tech
Write For Us Technology
Write For Us Gadgets
Technology Write For Us
Tech Write For Us
Gadgets Write For Us
Thanks for another wonderful post. Where else could anybody get that type of info in such an ideal way of writing? Applicant tracking system
ReplyDeleteborderlands 3 crack virus another review of the well known Borderlands arrangement. Generation is a first-individual shooter whose move makes put in an open world, and the entire is supplemented by components taken from the RPG type. The title was made by Gearbox Software studio, in charge of the initial two perspectives and the Brothers in Arms arrangement. Borderlands 3 features bazillions of guns, courtesy of the same reputable manufacturers that Vault Hunters like you have been trusting to tool them up since forever. Guns that grow legs and chase down enemies while hurling verbal insults? Yeah, got that too. At the hard edge of the galaxy lies a group of planets ruthlessly exploited by militarized corporations. Brimming with loot and violence, this is your home the Borderlands. Now, a crazed cult known as The Children of the Vault has emerged and is spreading like an interstellar plague.
ReplyDeleteinvestigación Infidelidades is a very serious matter and should be done by professionals. In a delicate moment it is very easy to fall into the commission of crimes against privacy yourself or to hire a "pirate" who commits crimes with you without having the least idea of the limits of the current legislation. Only a professional private detective knows what and how to investigate to achieve results without breaking any law.
ReplyDeleteRazer Surround Pro Key Complete Crack + Patch Free of charge Download
ReplyDeleteRazer Surround Pro Key could be the capable virtual encompass sound motors which intrigue you under into the amusement. It presents you gamer the most effective virtual 7.1 channel encompass sound contact with any stereo earphones. You could potentially see the sweet good encounter gaming that will fall you on your amusements within a by means of existing day way. It will be pleasing with any earphones, headset, and headphones. One can go towards changing into history with an remarkable recognition of other’s anticipations inside of your titles by means of our irregular point out sound
Rajasthan High Court LDC Retirement
ReplyDeleteRajasthan Forest Guard Recruitment
SSC Stenographer Recruitment
Watch the latest Turkish series, dubbed and subtitled online, full episodes in high quality YouTube Download the latest and newest exclusive Turkish series with a direct link مسلسلات تركية
ReplyDeletewatching porn porn videos collection. HD quality watching porn xxx movies for free of charge . Fresh videos a day سوكس بنات نيك
ReplyDeleteWhether you're new to angling or you're experienced, at Total Fishing Tackle you may discover all of the accessories, clothing and equipment you need, today Ivan Susanin
ReplyDeleteWatch right here your Favourite Pinoy Tambayan Channel Replay television shows Online. All The Filipino Replays and Pinoy Lambingan shows Available for You.
ReplyDeleteThis excellent website truly has all of the info I wanted concerning this subject and didn’t know who to ask. 베토리카지노
ReplyDeleteFind and share regular cooking idea on Allrecipes. Discover recipes, cooks, videos, and how-tos based at the food you love and the friends you follow. lovely recipes
ReplyDeleteI have read your blog and its really interesting.
ReplyDeleteMy Blog: Printer Installation Error 0x000003eb appears mainly when trying to perform a usual and familiar connection or installation of a printer in the system. check blog for simple & easy Solution.
This is my first visit to this territory. I find some really spellbinding things about this discussion in your blog. Remain mindful of the incredible work. Website: HP Error Code B0605
ReplyDeleteUK 49s Ltd. organizes this lotto, and the occasion attracts instances a day. So it’s a double chance for lunchtime gamers who desires to double the win! The below schedule is about timing suitable for playing. UK lunchtime results
ReplyDelete
ReplyDeleteI am really impressed with the information you provide in your post. Looking forward to visiting more.
Epson printer error code 031008
Watch the latest Indian series, dubbed and subtitled, complete series in high quality online. Watch directly YouTube full episodes مسلسلات هندية
ReplyDeleteResources like the one you mentioned here will be very useful to me! Thanks for sharing this useful information with us...Check out the way to fix Dell Error Code 2000 0122. Lean how you can fix it at your own or feel free to call our experts on our toll-free numbers or visit our website to know more!
ReplyDeleteThis article was really good. Thanks for sharing this one. I'll surely be visiting this site again. Check out the way to fix Dell Error Code 0141. Lean how you can fix it at your own or feel free to call our experts on our toll-free numbers or visit our website to know more!
ReplyDeleteNice
ReplyDeleteTechnewsinfo gives you a voice through which you can reach a global audience, and our strong positioning in Search Engine makes the readers find your articles first.
Technology write for us
Honey Web Solutions was founded in the year 2012, which specializes in web development, website design, eCommerce development, Web Application, Custom Development, flash,Digital Marketing and SEO. visit:Digital Marketing Company in Tirupati
ReplyDeleteHoney Web Solutions was founded in the year 2012, which specializes in web development, website design, eCommerce development, Web Application, Custom Development, flash,Digital Marketing and SEO.visit:Digital Marketing Company in Tirupati
ReplyDeleteDr. Ram Manohar Lohiya Avadh University Bachelor of Commerce Semester wise Exam Result 2020 now available online. Students Can Check 1st 2nd 3rd Year BCom Result 2020-2021.
ReplyDeleteDr. Ram Manohar Lohiya Avadh University Exam Result
RMLAU Bcom Exam Result 2020
RMLAU Bcom 3rd Year Result 2019-20
This comment has been removed by the author.
ReplyDeleteGood news My heart's desire came to your website suddenly.
ReplyDeleteMark it for the moment!
freemake video downloader crack
ReplyDeleteAfter studying many pages on your site, I love your blog.
I have added it as a book to my catalog and will see it longer.
Please check out my website and let me know what you think.
bandicut crack
foxit reader crack
transmac crack
mirillis action crack
I’m very pleased to find this page.
ReplyDeleteThis is very attention-grabbing, You’re an overly skilled blogger.
ReplyDeleteI’ve joined your feed and look ahead to seeking more of your great post.
Additionally, I have shared your site in my social networks
hard disk sentinel crack
freemake video downloader
k7 antivirus premium
any video downloader pro crack
rocket cleaner apk
This is very attention-grabbing, You’re an overly skilled blogger.
ReplyDeleteI’ve joined your feed and look ahead to seeking more of your great post.
Additionally, I have shared your site in my social networks
xilisoft iphone magic platinum crack
asmw pc optimizer pro
truecaller premium apk
Extraordinary site you have here.. It's elusive quality composing like yours nowadays. I sincerely acknowledge people like you!
ReplyDeleteonevanilla gift card,
onevanilla check balance,
AU BA 1st year Exam Date Sheet
ReplyDeleteNice post, I really enjoyed reading this article, it explains everything in a simple way. I will be reviewing this blog for such important information and will continue to search for it.
ReplyDeletemovavi video editor
typing master pro crack
driver easy crack
windows activator crack
I really like what you all put up. you have completed honestly appropriate work. thank you for the information you provide, it helped me plot Matlab R2020 Crack & License Key pubg license key crack.
ReplyDeleteWhat are you waiting for?. just go through this website and get them free.
ReplyDeletecrackkits
crackskit
ijicrack
vmix crack
reiboot pro crack
tenorshare reiboot pro registration code
Thank you very much for sharring this website here.
ReplyDeletecrackprovst
crackprime
ijicrack
stardock fences crack
voicemod pro free crack
soundtoys 5 mac crack
jrnrvu B.com Time Table
ReplyDeleteI am really impressed with the information.I look forward to more comprehensive and insightful posts like this in the future. Thanks for your post. keep it up!
It is my first visit to your blog, and I am very impressed with the articles that you serve. Give adequate knowledge for me. Thank you for sharing useful material.
ReplyDeleteuniraj bsc time table 2021
davv bsc time table 2021
It kind of feels that you're doing any distinctive trick. Moreover, The contents are masterpiece.
ReplyDeleteyou have done a fantastic activity on this subject!
microsoft office 2013 crack free download
microsoft office 2016 Product key activator free download
microsoft office 2019 Crack free download full version
microsoft office professional 2010 serial key
microsoft office 365 serial key crack free download
fl studio crack unlock file free download
Magoshare Data Recovery free Activation Key Download
Grammarly Crack with Premium Account License Key Free download
Chimera Tool Pro Crack free donwload
Omnisphere Crack activation key Free Download
Thanks for giving me grateful information (Rajasthan police constable result) . I think this is very important to me. Your post is quite different. That's why I regularly visit your site.
ReplyDeletethank you for share this post Tech write for us
ReplyDeleteyowhatsapp
content com android browser
zinitevi
Cotomovies
Thanks for sharing this post. Hi, Myself coren fozz. We are working dedicatedly as an independent and reliable third-party tech support provider, available round the clock to provide the best technical support services for brother printer users. If you are experiencing brother printer doesn't recognize ink cartridge error, our printer support professionals have the great technical skills and extensive experience for resolving this technical error within a few seconds.
ReplyDeleteLove Candy Jack strain. Use it to treat MS symptoms, and it works quickly and very well. Tastes wonderful
ReplyDeleteWoah! I’m really enjoying the template/theme of this website.
ReplyDeleteIt’s simple, yet effective. A lot of times it’s very
difficult to get that “perfect balance” between user friendliness and appearance.
I must say that you’ve done a very good job with this.
Also, the blog loads very quickly for me on Firefox.
Exceptional Blog!
iobit malware fighter crack
guitar pro crack
playon crack
agisoft photoscan crack
adobe photoshop cc crack
adobe photoshop cc crack
Applications for Windows, Mac, Linux and Smartphones, Games and Drivers
ReplyDeleteApplications
Great website! It looks extremely professional! Sustain the helpful job! Cubase Pro Pro Full Crack.
ReplyDeleteIt’s actually a cool and useful piece of info. I’m happy that you shared this useful info with us. Please stay us informed like this. Thank you for sharing Corel Aftershot Pro 3.7.0.446 Crack + Serial Key Free Download.
ReplyDeleteExceptionally user pleasant website. Enormous info readily available on couple of clicks https://seeratpc.com/macrorit-partition-expert-crack/
ReplyDeletebarrel sauna with wood stove
ReplyDeleteWAJA sauna is specialist manufacturer of top quality sauna products. Products include sauna rooms, steam rooms, barrel saunas, wooden hot tubs, and all kinds of sauna accessories.
Hello I am so delighted I located your blog about 안전놀이터, I really located you by mistake, while I was watching on google for something else, Anyways I am here now and could just like to say thank for a tremendous post and a all round entertaining website. Please do keep up the great work.This is a great post!I didn't overdo it because of the inflated content , and I feel that I tried to keep the reader from 토토사이트 feeling the burden with concise content.
ReplyDeletethanks for shring this post its really amazing we offer best kashmir tour travel services
ReplyDeletebudget Kashmir holiday
Valley trip tour operator
honeymoon packages for kashmir
Thanks for other great articles, others might get it.
ReplyDeleteWhat kind of knowledge is such an ideal form of writing? I am the owner
I looking for so a presentation in a week.
advanced systemcare pro serial key
reimage pc repair crack
adobe illustrator cc crack
fl studio 20 7 crack
easeus partition master crack
I feel that is among the so much important information for me. And i am satisfied reading your article. However should statement on few common issues, The site style is great, the articles is in point of fact great : D. Excellent process, cheers.
ReplyDeleteizotope insight crack
zwcad crack
netbalancer crack
graphpad prism crack
tenorshare icarefone crack
tiny cam monitor pro apk full cracked
mixpad crack
agisoft photoscan pro crack
autodesk autocad civil 3d crack
nice work is done here. thanks a lot for sharing.
ReplyDeletevisit
visit
visit
visit
If you have at any time believed about laying your own hardwood flooring all by yourself, that you must prevent to get a second. The problem is exactly what a hardwood floor nailer is. Allow us to speak about using a Flooring Nailer Reviews, once you become accustomed to it, it would make the job easy. This tool is built to sit on high of the tongue of the hardwood and drive the nails into it. It positions alone so you cannot come up with a blunder with it. This is certainly the sole tool in existence which is formed to nail hardwood flooring.
ReplyDeleteThe majority do not own a hardwood floor nailer, or have any notion what this tool is unless of course you may be inside of the construction firm. There are lots of regional merchants that you can discover these tools for hire. In the event you rent the nail gun, you may also need to have to hire the air compressor to run the nail gun. Rental is by the day or because of the week. You rent in accordance with the size of the job you have.
ReplyDeleteSend plants to Delhi - Order Unique plants Online from best gift shop, Gifola. Send latest unique plants to Delhi for all special occasions to your loved ones. ✓Free Home Delivery ✓Same Day Gift Delivery
Send plants to Delhi
NICE POST. KEEP UP THE GOOD WORK.
ReplyDeleteDOWNLOAD
THANKS FOR SHARING.
ReplyDeleteVISIT
crackedos
ReplyDeletePro Crack software Download
ReplyDeleteI like your all post. You have done really good work. Thank you for the information you provide, it helped me a lot. I hope
driver-genius-pro-crack
express-vpn-crack
winzip-pro-crack
bitdefender-free-edition-crack
avg-rescue-usb-crack
replay-music-crack
ontrack-easyrecovery-professional-latest-crack
Thank you for sharing such great information. can you help me in finding out more detail on 15 Best Google Chrome Security Extensions
ReplyDeleteThank you for sharing such nice post
ReplyDeletetechnology write for us
coto movies
zinitevi
yowhatsapp
kevin greene
Content Com Android Browser home
social media challenges
Best Chrome Security Extensions
thank you for sharign this post I am gald to be here and read this post
ReplyDeletecartoon hd
titanium TV for IOS
Cartoon HD Apk
Cotomovies apk
titanium TV for firestick
Android Apks - is a place where you can fiAndroid Apks - is a place where you can find paid best android apk apps games to download free full version for mobile, tablets.
ReplyDeletebrosec chrome
The Professional Edition of PaperScan Crack Scanner is the most comprehensive version that provides professional end users with all the necessary functions for efficient document (image and PDF) acquisition, processing and storage.
ReplyDeletePaperScan Pro Crack
KeepVid Pro Torrent presents up an archive course of action if you wish to record video, also to start out this all it's good to do is struck the devoted document button that rests beside the paste Web address button. Other providers which includes YouTube, MyVideo, Vimeo, Dailymotion, and CBS been employed by accurately. There is some techniques chances are you'll use to download video clips from loading online sites, in case you are any person who downloads an entire lot of promotion on the Internet https://kingsoftz.com/keepvid-pro-crack-serial-key/
ReplyDeleteGet help installing PC software on your computer, including installing software on Windows 10 devices, in this free lesson.
ReplyDeleteclownfish voice changer full
After looking through a few blog articles on your website,
ReplyDeletewe sincerely appreciate the way you blogged.
We've added it to our list of bookmarked web pages and will be checking back in the near
future. Please also visit my website and tell us what you think.
fullcrackedpc.com
Avocode crack
DriverMax Pro Crack
Avast Premium Crack
Ummy Video Downloader Crack
KMSAuto Net Activator Crack
I seriously love your website.. Excellent colors & theme.
ReplyDeleteDid you create this amazing site yourself? Please reply back as I’m attempting to create my own site
and want to know where you got this from or just what the theme is named.
Cheers!야동
Thats the the main reason i am your daily visitor because I love the way you write. Thanks for sharing this with us.
ReplyDeleteikcrack
hey
ReplyDeleteI enjoyed reading your post
ReplyDeletedigital marketing abuja
online marketing platforms in Nigeria
digital marketing agency lagos
digital marketing agency
I love your blog, thank you for sharing
ReplyDeletedigital marketing Lagos
digital marketing agency in abuja
I enjoyed reading through your post, thanks for sharing.
ReplyDeletexiaomi redmi 9
The product is painted with anti-scratch paint to help the cabinet stay beautiful for long-term use.
ReplyDeleteCrack
ablenton live Crack
acdsee pro Crack
acronis backup Crack
actual multiple monitors Crack
\crackgive.com
I’ll bookmark your Vidyasiri Scholarship blog and take a look at again right here regularly.
ReplyDeleteccs university.ac.in exam date sheet
Great post. Thanks for sharing your brain. Check mine out sometime.
ReplyDeleteThe Big Bull Full Movie Download & Watch
Pushpa Upcoming Movie Review
ReplyDeletepdf-xchange-editor-9-crack
sidify-music-converter-crack-download
totalfinder-crack-free-download
ashampoo-soundstage-pro-crack
pdf-xchange-editor-full-crack-latest-free
organiccrack.com/minitool-power-data-recovery-crack
brave-browser-crack-download
attendhrm-professional-crack-latest
bitdefender-free-edition-crack
I also believe A professional resource management tool can help you overcome the challenges of handling and allocating resources, helping you simplify and add efficiency to the process.
ReplyDeleteNice Blog !
ReplyDeleteOur team at QuickBooks Support Phone Number makes sure that we do everything possible to get your issues resolved in an unexpected moment of crisis.
Corel Draw Portable Portugues download
ReplyDeleteCorel Draw Portable Portugues
ReplyDeleteThanks for sharing such great information, I highly appreciate your hard-working skills which are quite beneficial for me. https://newcracksoft.com/aimersoft-video-converter-ultimate-crack/
ReplyDeleteHi
ReplyDeleteThanks for this topic. Unknown
found a web page with content that you might find interesting. If you're interested, please click the hyperlink..먹튀사이트
ReplyDelete
ReplyDeleteGood day! Writing this article couldn't get any better!
Reading this article reminds me of my wonderful roommate! He has already spoken about it.
I am sending you this article, are you sure?
You will read well Thanks for sharing!
poweriso crack
hotspot shield
eset smart security premium crack
iperius backup full crack
Guess I will just bookmark this site The Design looks very good 토토커뮤니티
ReplyDeleteWow, great blog article 먹튀검증 We are linking to this great post on our website
ReplyDeleteplay a very 토토사이트검증 important role in staying in touch with clients, delegates, and fellow employees.
ReplyDeletewritten I'm glad that i found this if only for the fantasti c lucidity in your writing. I will instantly grab안전놀이터
ReplyDeleteWindows 10 1507 version is not supported by this tool.
ReplyDeleteWindows 10 Activator
WINDOWS ACTIVATOR
Windows 10 Activator 2021
Windows 10 Activator Free Download
Good article, but it would be better if in future you can share more about this subject. Keep posting.
ReplyDeleteFeel free to surf to my page - 풀싸롱
(jk)
I'm amazed, I have to admit. Rarely do I encounter a blog that?s equally educative and amusing, and without
ReplyDeletea doubt, you've hit the nail on the head. The issue is something not enough men and
women are speaking intelligently about. I'm very happy I came across this in my
hunt for something concerning this.
Also visit my blog post; 오피사이트
Nice information provided by you, it really helped me to understand this topic. I have also referred this article to my friends and they also enjoyed this informative post. iZotope Insight 2 v2.1.1 Crack Mac/Win + Vst Torrent Free Download
ReplyDeleteBit.ly/Windowstxt
ReplyDeleteFree mobile and PC download games. Thousands of free Download or play free online! . Here is the Exact Arcade Version of Dig Dug!
ReplyDeletedownloadfreegameshere.com
Thanks for the post. Very interesting post. This is my first-time visit here. I found so many interesting stuff in your blog. Keep posting..
ReplyDeleteopencanvas-crack
download the wondershare pdfelement crack latest version. And edit your all office documents and more.
ReplyDeletewondershare pdfelement crack
ReplyDeleteI guess I am the only one who came here to share my very own experience. Guess what!? I am using my laptop for almost the past 2 years, but I had no idea of solving some basic issues. But thankfully, I recently visited a website named Azharpc.org that has explained an easy way to install all All the Crack software for Windows sand Mac.
Softros LAN Messenger crack
SpyHunter crack
ZIP Password Recover crack
Positive Grid Bias crack
Wondershare Video Converter Ultimate crack
MacKeeper crack
TunesKit Music Converter Crack for Spotify is fantastic software for Spotify music fans, whether you subscribe to a free or premium plan. This will help you download and convert your favorite songs from Spotify to MP3 or other standard formats fast and without loss.
ReplyDeletetuneskit-spotify-converter-crack
I really like your site. Fantastic colors and themes.
ReplyDeleteDid you create this site yourself? Reply again because I hope to create my own
site itself and I would like to know where you have come to
it is here or where the item is named from.
Thank you!
tally erp crack serial key
avg internet security crack
I was very happy when I found this place on the Internet.
ReplyDeleteI have to thank you at least once for this amazing read !!
I definitely liked it a bit and you saved it too
See something new on your site as a favorite
easeus partition master crack
driver talent pro crack
Sylenth1 Crack is a powerful and easy to use analog Absolute Studio Technology machine (VSTI) synthesizer, which takes the review and persona of the track to another level Sylenth1 splintering. There exist very few software synthesizers that have been able to stand up to the excellent quality standards of hardware synths.
ReplyDeletesylenth1-crack-serial-key
Nice article and explanation Keep continuing to write an article like this you may also check my website https://dmcrack.info Crack Softwares Download. We established Allywebsite in order to Create Long-Term Relationships with Our Community & Inspire Happiness and Positivity we been around since 2015 helping our people get more knowledge in building website so welcome aboard the ship.
ReplyDeleteWiFi Password Hacker Crack
iMyFone AnyrRecover Crack
Windows 8.1 Crack
Opera Crack
Wondershare Filmora X Crack
NCH MixPad Masters Edition Crack
Microsoft Office Crack
Download free for Netflix Crack For one humble month-to-month expense, you might look at however many recordings as you need, at whatever point you need, while never seeing a promotion.
ReplyDeleteBritish Citizenship Guidelines
ReplyDeleteYou can become a British citizen either by birth or you can apply for naturalisation if you are aged 18 or over.
You must prove that you are British and have not broken any UK laws, including immigration violations, to be eligible for British citizenship.
After your request for permanent residence status is approved, you are able to live, work, and study in the UK without restrictions.
Your status will not be affected by your ability to travel or spend time abroad.
Get in touch with our professional immigration lawyers to learn more about how you can obtain settled status in the UK.
Naturalisation-Registration-as-British-Citizen.php.
https://crackcool.com/babylon-pro-ng-crack/
ReplyDeleteIt is comfortable and easy to use. Choose to upload your document to your desktop translator by clicking on the “Document translation” tab, or periodically translate the document directly
dc unlocker crack
ReplyDeleteDC-Unlocker Crack Client is a new software that unlocks phones, modems, and routers. With this tool, you can easily unlock all internal and external modem models without effort and cost. Used to unlock cables and adapters for free unlocking. Also, the user can easily open a data card on a laptop based on a PCMCIA or Express socket. In this latest version of DC-Unlocker Crack, all new models have been added. Also, the user can easily open a data card on a laptop based on a PCMCIA or Express socket. In this latest version of DC-Unlocker Crack, all new models have been added.
https://crackxpoint.com/easeus-mobimover-crack/
ReplyDeleteEaseUS MobiMover 5.6.0 Crack is one of the best tools that usually works on the data recovery tool. Therefore, this tool is much handly and use to get all system features. While this tool is about to restore all the installed data and also help to delete the data. While you will use it to restore the data and make any kind of backup data. Also, the tool is there and makes the data to help many types of features.
https://keyscracked.com/360-total-security-cracked/
ReplyDelete360 Total Security Crack is most likely use to get a safety suite that has ever reviewed. If you are looking for the full safety of your system then use this app. `And it can look on paper that fact is ugly in the filled with issues. Therefore, the anti-virus engine that uses by default there is feeble that can stop malware. Along with the ransomware that gets ruin and has got on all PC. 360 Total Security, Therefore, that users and download and install this security package. And it gets unattended from a variety of threats.
https://whitecracked.com/ccleaner-pro-crack-with-key/
ReplyDeleteCCleaner Pro 5.84.9126 Crack is the most loyal software to clean and defend your device system completely. It is pro-acknowledged software. That is very light and understandable to use. Further, this is really suitable for Mac and also for Windows OS. Further, this thoroughly scans your device and erases malware, junk files, and many other items. Also, the software presents all the PC performance results. It’s the most immeasurable program for the safety of your computer. This examines your Windows registry and excludes all obstacles.
"First of all I would like to say awesome blog! I had a
ReplyDeletequick question that I'd like to ask if you do not mind. I was interested to find out how you center yourself and clear your thoughts before writing.
I have had a tough time clearing my mind in getting my thoughts out.
I do enjoy writing but it just seems like the first 10 to 15 minutes are wasted just trying to figure out how to begin. Any recommendations or tips?
Kudos!"
Review my homepage ➤ 야설
Hey there 오피! Someone in my Myspace group shared this site with us so I came to look it over.
ReplyDeleteI’m definitely loving the information. I’m book-marking and will be tweeting this to my followers! 외국인출장
ReplyDeleteInteresting stuff to read 성인야설 . Keep it up. This is very informative and interesting for those who are interested in blogging field.
ReplyDelete"Undeniably imagine that which you stated. Your favorite reason seemedto be at the net the easiest factor to take note of. I say to you, I definitely get irked at the same time as people consider issues that they just do not recognise about. You controlled to hit the nail upon the highest and also defined out the entire thing with no need side effect, other people can take a signal. Will likely be again to get more. Thank you 립카페"
ReplyDeleteFound your post interesting to read 안마. I cant wait to see your post soon. Good Luck for the upcoming update.This article is really very interesting and effective.
ReplyDeleteThis paragraph gives clear idea for the new viewers of blogging,Thanks you 무료야설 .
ReplyDelete
ReplyDeleteRACESITE.PRO
August 3, 2021 at 1:01 pm
Remarkable! Its really amazing post, I have got much clear idea regarding from
this piece of writing 룰렛
Remarkable! Its really amazing post, I have got much clear idea regarding from
ReplyDeletethis piece of writing. 온라인카지노
I am extremely impressed along with your writing skills as well as with the structure in your blog. Is that this a paid theme or did you customize it your self? Anyway stay up the excellent quality writing, it is rare to look a great blog like this one these days..click me here온라인바카라
ReplyDeleteyyy
This was an extremely nice post. Taking a few minutes and actual effort to generate a top notch article.바카라사이트
ReplyDeleteNice post. I learn something more challenging on different blogs everyday. 카지노사이트 It will always be stimulating to read content from other writers and practice a little something from their store. I?d prefer to use some with the content on my blog whether you don?t mind. Natually I?ll give you a link on your web blog. Thanks for sharing.
ReplyDeleteThat is a really good tip especially to those fresh to the blogosphere.
ReplyDeleteclick me here카지노사이트
yang
Simple but very accurate info... Many thanks for sharing this one.
ReplyDeleteA must read post!
click me here바카라
yang
카지노사이트홈 Awesome! Its genuinely awesome paragraph, I have got much clear idea on the
ReplyDeletetopic of from this paragraph.
ABC Assignment Help offers unique myassignmenthelp
ReplyDeletethrough actual professionals. Our team of PhD. certified experts strive to satisfy students’ expectations along side University guidelines to make sure high scoring assignments whenever . along side writing help we also offer proofreading, editing, free samples and exam help to help students in achieving their career aspirations.
best software-------->SoundToys Crack is a unique audio effect software that is critical to modern digital music production in studios.-----------> SoundToys Crack
ReplyDeleteI was impressed by your writing. Your writing is impressive. I want to write like you.안전놀이터 I hope you can read my post and let me know what to modify. My writing is in I would like you to visit my blog.
ReplyDeleteAnd I admire your work, I am an excellent blogger.
ReplyDeleteMy interest was greatly distracted by this article.
I'll bookmark your website and keep searching for new information.
repla music crack
videoproc crack
soundtap streaming audio recorder crack
Great Job Azmaing content and blog Thanks For this nice content
ReplyDeletelogic-pro-x-crack
How ZR Tech Can Help?
ReplyDeleteAt ZR Tech, we offer provide data solutions that enable you to collect,
organize and activate data to help you reach your business goals.
ZR-Analytics helps you to understand users need and
collect data according to your business service.
Plus, our team will be by your side every step of the way.
Visit here: https://www.zr-tech.co.uk/ZR-Analytics/
ReplyDeletehttps://rootcracks.org/phpstorm-activation-keys-cracked-2021/
PhpStorm Activation Code gives an editor to PHP, HTML, and JavaScript with on-the-fly code analysis, blunder prevention, and mechanized refactorings for PHP and JavaScript code. The key is based on IntelliJ IDEA, which is written in Java. Clients can expand the IDE by installing plugins created for the IntelliJ Platform or compose their modules.
https://licensekeysfree.com/deezer-apk-premium/
ReplyDeleteDeezer Premium Crack is the advanced unlocked edition that provides a free experience to the users. On the other hand, this app helps the users enjoy various sorts of high quality and they even don’t have to subscribe to it. Moreover, this app comes with almost fifty-six millions of the titles and a great amount of the Spotify and Tide.
https://cracklabel.com/tableau-desktop-crack/
ReplyDeleteTableau desktop Torrent can be really a favorite resource of updates and news on earth. It’s possible for you to take advantage of this program to test the info. What’s more, it gives you the ability to produce a record of one’s own data. It’s a helpful program for organization brains. Thus, you may take advantage of this program to handle the figures tool. While having since you desire
ReplyDeletehttps://whitecracked.com/ableton-live-crack-keygen/
Ableton Live Cracked was written in C ++ and was first released in 2001 as one of the commercial software. As it was a prototype in Max / MSP. But it uses in some models of audio devices. Version 8.4 Windows, Macintosh also compatible with 64-bit. However, it has some features.
When I read your article on this topic, the first thought seems profound and difficult. There is also a bulletin board for discussion of articles and photos similar to this topic on my site, but I would like to visit once when I have time to discuss this topic. 안전토토사이트
ReplyDeleteI surprised with the research you made to create this actual post incredible.
ReplyDeleteFantastic job!
click me here온라인카지노
6yang
Guess I will just bookmark this site This is the kind of info that should be shared across the net. 토토커뮤니티
ReplyDeleteI can grow up with. Please continue to do well and always do well 먹튀사이트 We are linking to this great post on our website
ReplyDeleteI'm reading it well. This is something that Thank you for your always good posts 토토검증
ReplyDeleteRah quel coup de crayon ! Je ne post pas souvent, mais je dois bien admettre que je suis admiratif de tous tes dessins. 토토검증
ReplyDeleteBest blog Good work keep it up
ReplyDeletestartisback-full-version
Best blog Good work keep it up
ReplyDeleteglasswire-crack
Best blog Good work keep it up
ReplyDeletepdf-xchange-pro-full-version
I finally found what I was looking for! I'm so happy. 안전한놀이터 Your article is what I've been looking for for a long time. I'm happy to find you like this. Could you visit my website if you have time? I'm sure you'll find a post of interest that you'll find interesting.
ReplyDeleteAt first glance, my first choice is an efficient application.
ReplyDeleteIn short, reliable user feedback has made it possible to download personal files and keep them safe.
medusa pro crack
thea render crack
vsdc video editor crack
Techsreader is sharing valuable information related to Technology and all the latest updates.
ReplyDeleteTechnology Write for us
A very awesome blog post. We are really grateful for your blog post. You will find a lot of approaches after visiting your post.
ReplyDeleteHi! We are Best Water Treatment Companies in UAE Great points made up above! And
Alkaline RO Water Filter System thanks…
I think this is one of the most important information for me. And i am glad reading your article. But should remark on few general things…
Thanks for sharing such a great post. Nice Post I Enjoyed!
ReplyDeleteCCleaner Professional Crack
FlixGrab Crack
Nice-------> Idle Planet Miner Crac
ReplyDeletePush Video Wallpaper Crack
Global Mapper
VueScan Pro Crack
Chris-PC CPU Booster Crack
Windows KMS Activator Ultimate Crack
Wonderful work! This is the kind of info that are meant to be shared across the internet. Disgrace on the search engines for not positioning this post higher! Come on over and consult with my website.
ReplyDeleteSo, I would like to Share Avast Premium Security Crack with you.
Adguard Premium Crack
Nice-------> Ashampoo Soundstage Pro
ReplyDeletePC Reviver
GiliSoft Video Converter
CorelDRAW Graphics Suite Crack
VideoPad Video Editor Pro
Titan FTP Server Enterprise Crack
using this amazing Software.
ReplyDeleteControlMyNikon Pro Crack
Screenpresso Pro Crack
zoom player max Crack
WinZip Pro Crack
Soni Typing Crack
Bluesoleil
ReplyDeleteCrack is a multi-functional program. It is designed to wireless connect Bluetooth devices to a laptop or computer. This is a utility known to many users for connecting a PC to various devices. connect a printer.
Duplicate Cleaner Pro Crack
Office Suite Pro Apk Crack
Drivermax Pro Crack
Bluesoleil Activation Key
Blufftitler Crack
Appreciate your content and really overwhelmed with what you have written right now. We have our own technology blogs which tells lot about technology... If you want to contribute just search technology write for us in Google serp
ReplyDelete
ReplyDeletestellar data crackk
ReplyDelete40 most famous paintings From Justincanvas.com
Buy Gelato Strain
ReplyDeleteBuy G-13 Haze Kush
Ghost Train Haze
Woah! I’m really digging the template/theme of this website. It’s simple, yet effective. A lot of times it’s difficult to get that “perfect balance” between usability and visual appeal.
ReplyDelete토토사이트
경마
I like what you guys are up too. Such clever work and reporting! Keep up the superb works guys I¦ve incorporated you guys to my blogroll. I think it’ll improve the value of my site
ReplyDelete카지노
토토사이트
Therefore, Smart Game Booster Activation Key is a touchpad that can control clicking, scrolling, dragging, and tapping. Besides, it gives the feature to overlook the GPU and the CPU gets the optimal visual effects. Such as, it gives you many latest features.
ReplyDeletehttps://keypccrack.com/smart-game-booster-crack/
Nice explanation and article. Continue to write articles like these, and visit my website at https://usacrack.info/ for more information.
ReplyDeleteKutools For Excel Crack
Thank you for some other informative blog. Where else could I get that type of information written in such an ideal means? I have a mission that I’m just now working on, and I have been at the look out for such information. 먹튀검증 It helped me a lot. If you have time, I hope you come to my site and share your opinions. Have a nice day.
ReplyDeleteVery nice post. keep going by posting such great contents. Very interesting and meaningfull content
ReplyDeletecowkart
cowkart
We are the Digital Marketing Agency in the UK .Our team of experts has been helping businesses grow online since 2013, and we’re proud to be DM EXPERTS one of the most trusted agency in London. With our expertise, your business will have more customers than ever before!
ReplyDeleteThis is amzaing blog thanks for that great information. Thanks!
ReplyDeleteplex-media-server-crack
altium-designer-crack
mirillis-action-crack
yeah, This is great place where we collected such a nice informations. Thank you!
ReplyDeletemovavi-slideshow-maker-crack
ableton-live-crack-torrent
gitkraken-crack
This is amzaing blog thanks for that great information. Thanks!
ReplyDeletereason-crack/
altium-designer-crack
mirillis-action-crack
ReplyDeleteUniPDF PRO Crack
Magic Browser Recovery Crack
Thanks for sharing this informative post. I recommend keep sharing like this. I also recommend to visit myassignmenthelpwebsite for amazing blogs and assignment writing service in Australia.
ReplyDelete
ReplyDeleteUltraiso crack can help you deal with ISO images. You can also use it to
convert, generate or modify ISO images of DVD / COMPACT DISC. This software includes simple and easy use of the software.
It consists of a variety of features to enable you.
Thank you for this post. This is very interesting information for me. Razer Surround Pro activation
ReplyDeleteI definitely enjoying every little bit of it and I have you bookmarked to check out new stuff you post. ivt bluesoleil crack
ReplyDeletePercent Query Coverage is the percent of the query length that is included in the aligned segments.autodesk maya crack
ReplyDeleteGoogle Scholar.
ReplyDeletevueminder ultimate crack
hi Dear, Thank you for sharing your details and experience. I think it very good for me. Keep it up! Also May you like Turbocollage Crack
ReplyDeleteMobinkin DR for andriod Crack
ReplyDeleteapplications that we consider in the following paragraphs can retrieve all the user’s information with a few simple
and easy clicks. Due to this fact, this system can recover deleted information easily and quickly.
anti porn with crackLanguages like C#, Java, C++ and others are more popular among professional developers. However, you don't have to be a developer to write applications
ReplyDeleteWhat a great website you have! I particularly liked the format and presentation of the data.
ReplyDeleteIt would be great if you could inform me whenever a new post is made.
Ashlar-Vellum Graphite Crack
Very interesting article. It would be great if you could provide more details about this Article. Great Article. I am learning to be social on SM and learning to blog etc. So all your info helps.
ReplyDeleteArticulate storyline Crack
AAct Portable Crack
I am very happy to read this article. Thanks for giving us Amazing info. Fantastic post. I appreciate this post.
ReplyDeletezoner-photo-studio-x
altium designer 18 crack is a world leader in electronic automation. This is an excellent and
ReplyDeleteinteresting program.
amiduos crack is nothing at all
ReplyDeleteunder the full Android knowledge, the system the characteristics the most recent edition of the well-known mobile os needs to provide.
dgflick album xpress pro 12.0 crack free downloadThe Quaternary spans from 2.58 million years ago to present day, and is the shortest geological period in the Phanerozoic Eon.
ReplyDeleteduplicate cleaner pro 4 license keyKnowledge Work Systems.
ReplyDeleteManagement Information Systems.
gstarcad crackLikeable — He's easy to like.
ReplyDeleteIt solved all my queries perfectly. Our HP Printer offline service is also offered to get your printer offline.
ReplyDeleteOur HP Printer offline service is also offered to get your printer offline.
schoolhouse-test-crack/
I was looking for this information from enough time and now I reached your website it’s really good content.
ReplyDeleteThanks for writing such a nice content for us.
avast-cleanup-premium-key/
Hi dear, It is very enjoyable to visit Your website because you have such an Amazing Writing Style.
ReplyDeleteMany thanks for the shared this informative and Interesting post with us
mIRC with Crack
Thank you for writing such a great informative article for today's modern readers. Two thumbs up for great content and interesting views.s
ReplyDeleteatomic mail sender
You have done great article work. Your website is extremely useful. Kindly keep us informed about your work.
ReplyDeleteCyberGhost VPN Crack
Dear, I have recently started a website, the info you provide on this site has helped me greatly. Thank you for all of your time & work.
ReplyDeleteAmiBroker Serial Key
What is the best antivirus for Windows 10?
ReplyDeleteThe best Windows 10 antivirus you can buy
Kaspersky Anti-Virus. The best protection, with few frills. ...
Bitdefender Antivirus Plus. Very good protection with lots of useful extras. ...
Norton AntiVirus Plus. For those who deserve the very best. ...
ESET NOD32 Antivirus. ...
McAfee AntiVirus Plus. ...
Trend Micro Antivirus+ Security.anytoiso-professional with crack download latest
ReplyDeleteit has a simple and easy to use interface. I've been using it for a long time and it is the best one indeed. Thanks for post this blog,is magnificent software for greater results of your task.
https://cracktrue.com/razer-surround-pro-7-2-crack-activation-key-2021-latest/
Wonderful work! This is the kind of info that are meant to be shared across the internet. Disgrace on the search engines for not positioning this post higher! Come on over and consult with my website. kitchendraw 6.5 full
ReplyDeleteYou have a wonderful website! I particularly enjoyed the format and presentation of the information.
ReplyDeleteWould you be able to notify me whenever a new post is made?
CyberLink PowerDirector Crack